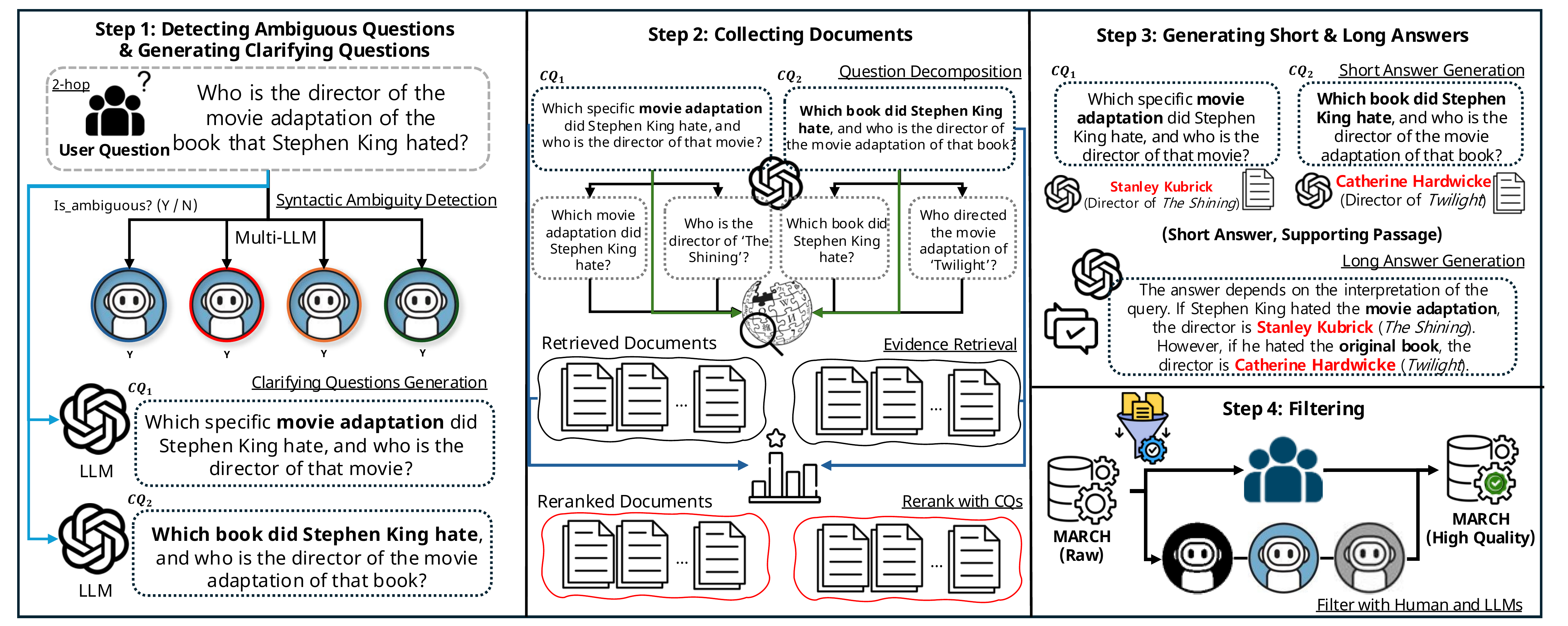
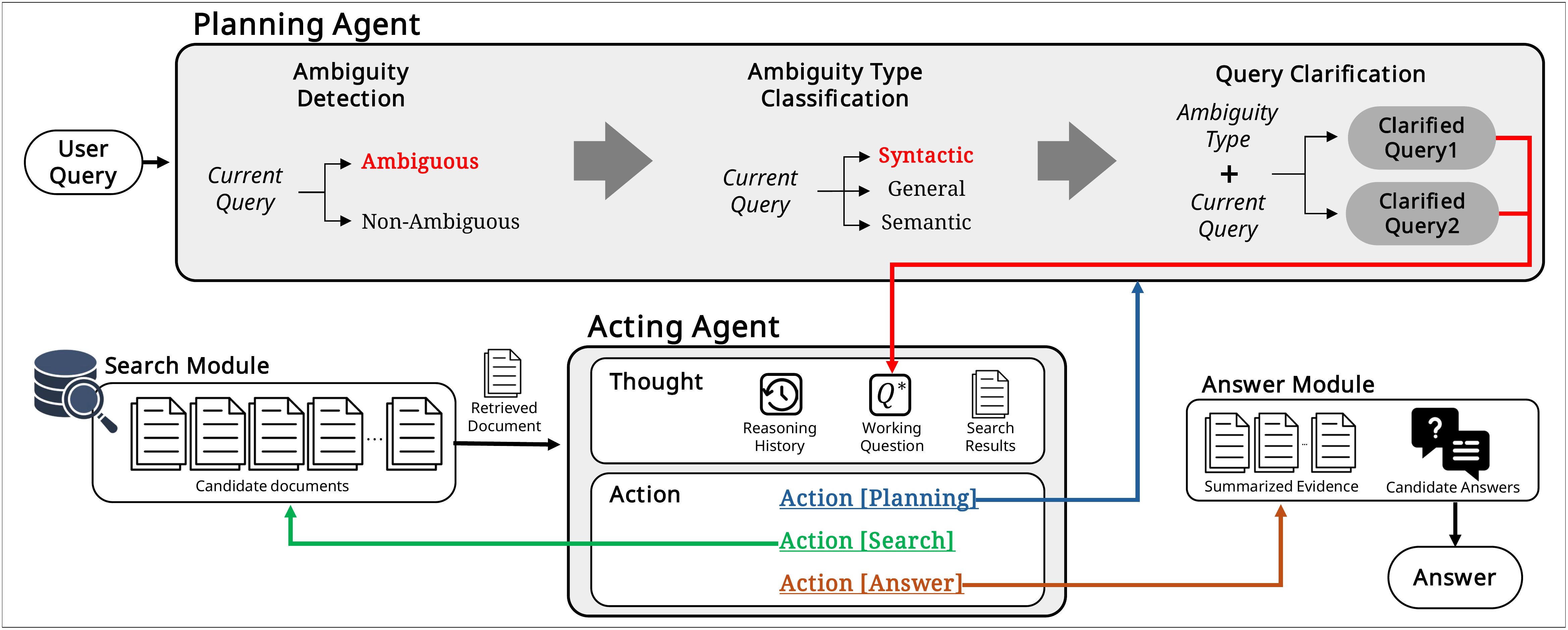
Motivation
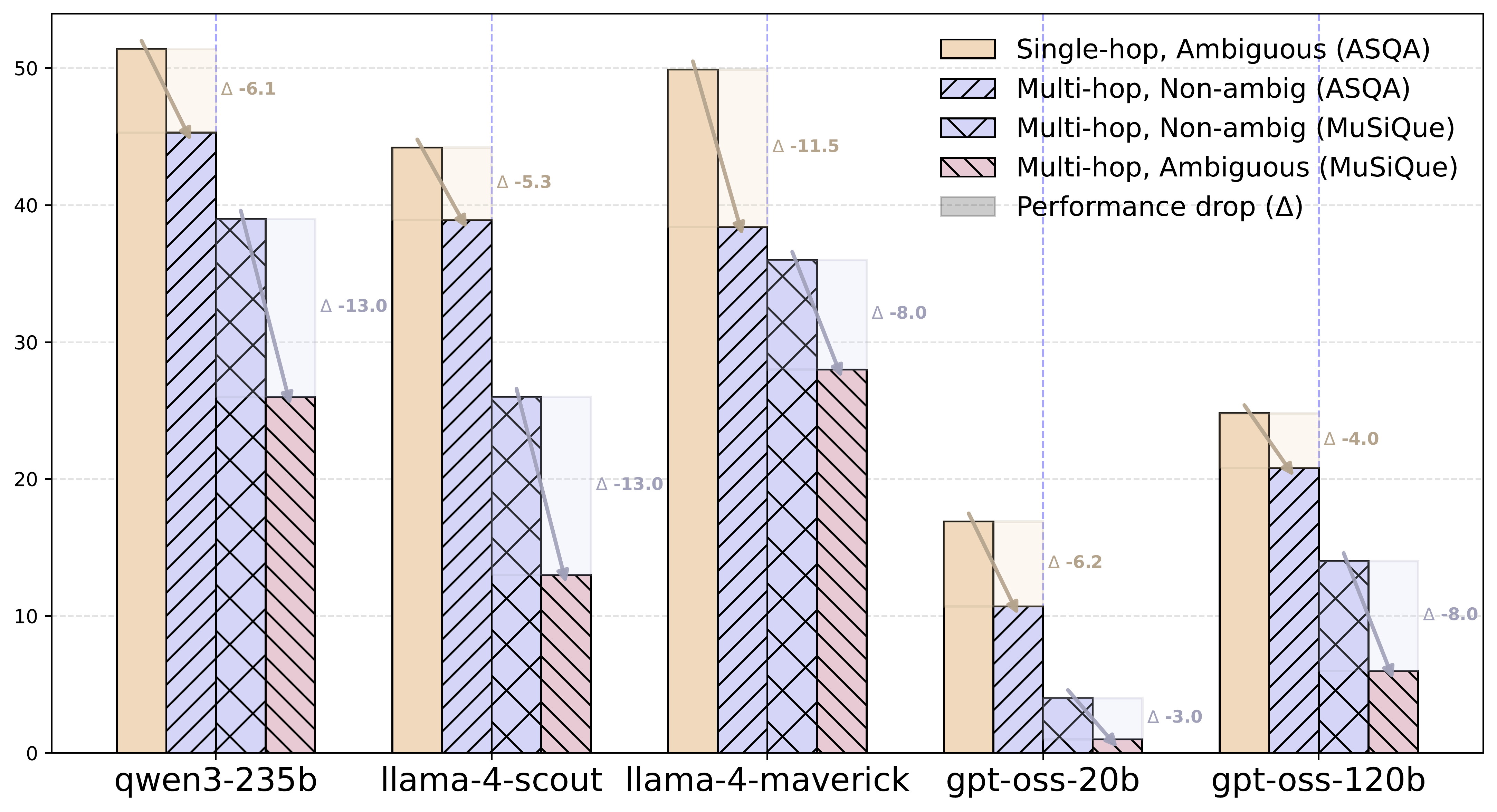
Multi-hop QA requires constructing logical chains across multiple documents. When ambiguity is introduced, uncertainty scales exponentially—ambiguity can emerge at any step, often remaining latent until prior steps are resolved.

Semantic
Interpret
Homonyms or entity-name collisions yielding disjoint evidence trails. The wrong entity invalidates downstream hops.
"Mustang" → Ford (car) vs. Fender (guitar)
Syntactic
Resolve
Multiple valid parses induce different inter-hop dependencies, changing which intermediate evidence is needed.
Instrumental vs. Attributive reading of telescope question
Constraint
Generalize
An over-specific modifier causes a valid chain to be pruned early. Relaxing the constraint recovers the path.
"highest mountain in Europe" → Mont Blanc vs. Elbrus
Real-world prevalence: Analysis of lmsys-chat-1m reveals 48.4% of questions are ambiguous, 17.7% involve multi-hop reasoning, and 13.3% overlap—yet no benchmark specifically targets this intersection.