Motivation
Language preference is a critical issue in mRAG systems that leads to inaccurate outputs. The retriever may prioritize particular languages—especially high-resource or query-language documents—at the expense of truly relevant information. Even when relevant documents are retrieved, the generator might favor passages in Latin scripts, ignoring essential evidence in other languages.
RQ1 §4
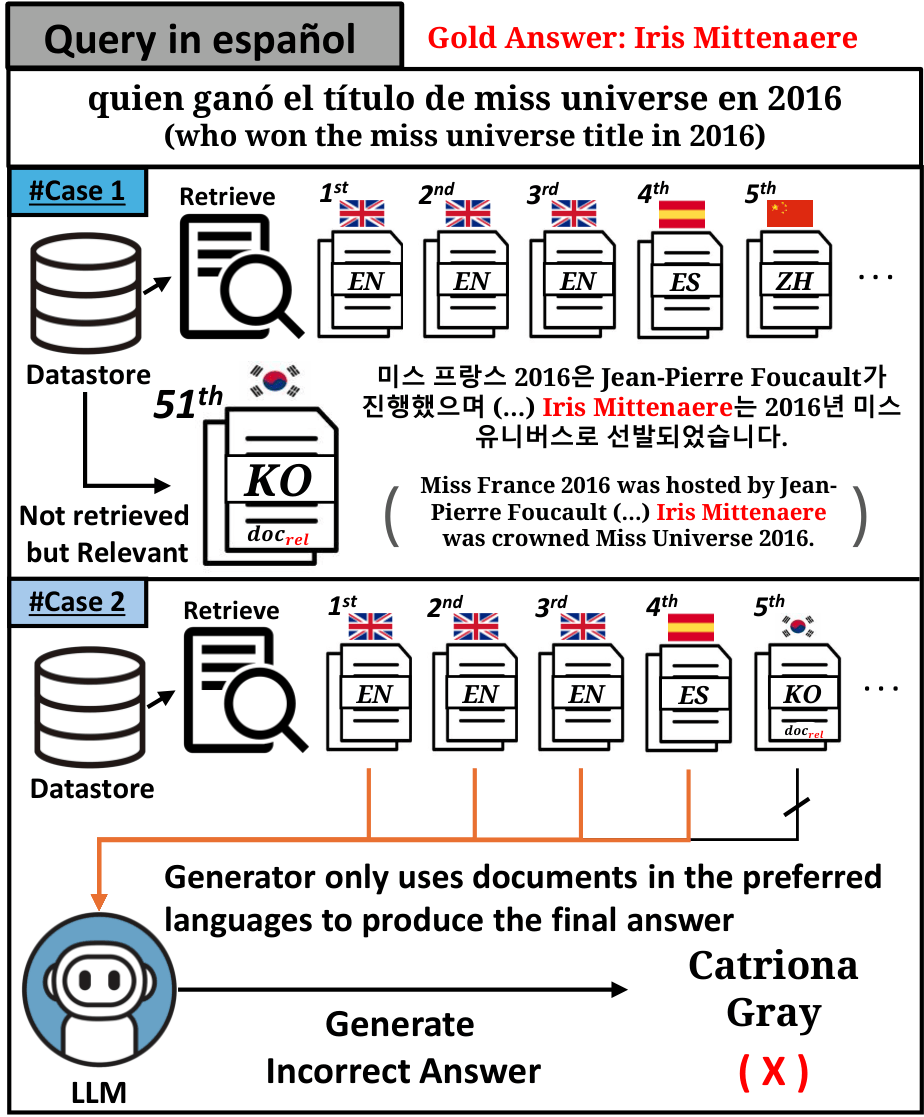
Retriever Preference
Which languages does the retriever prefer, and how do query-document language relationships affect ranking?
RQ2 §5
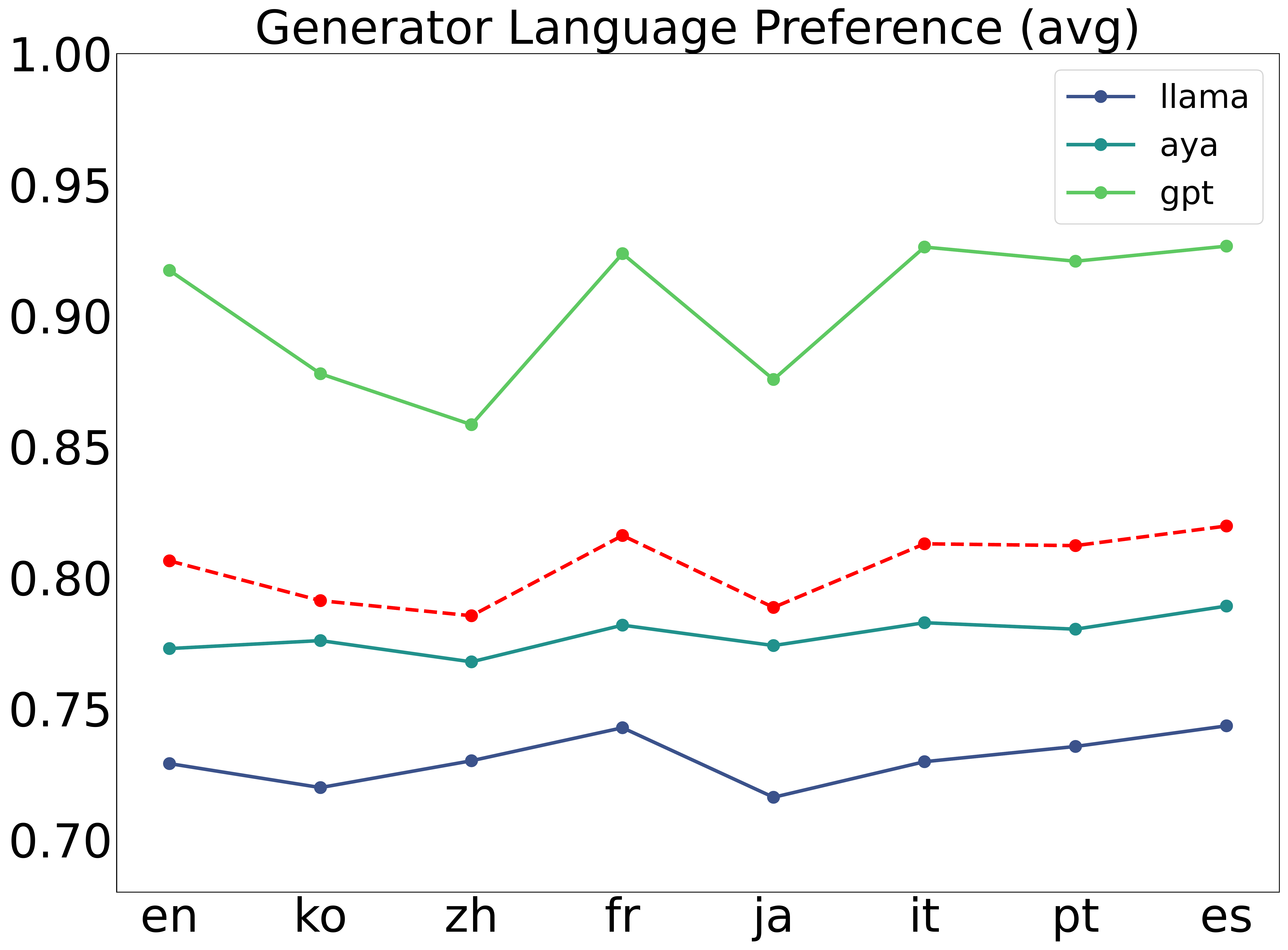
Generator Preference
Which languages does the generator prefer, and how do these preferences correlate with mRAG performance?
RQ3 §6
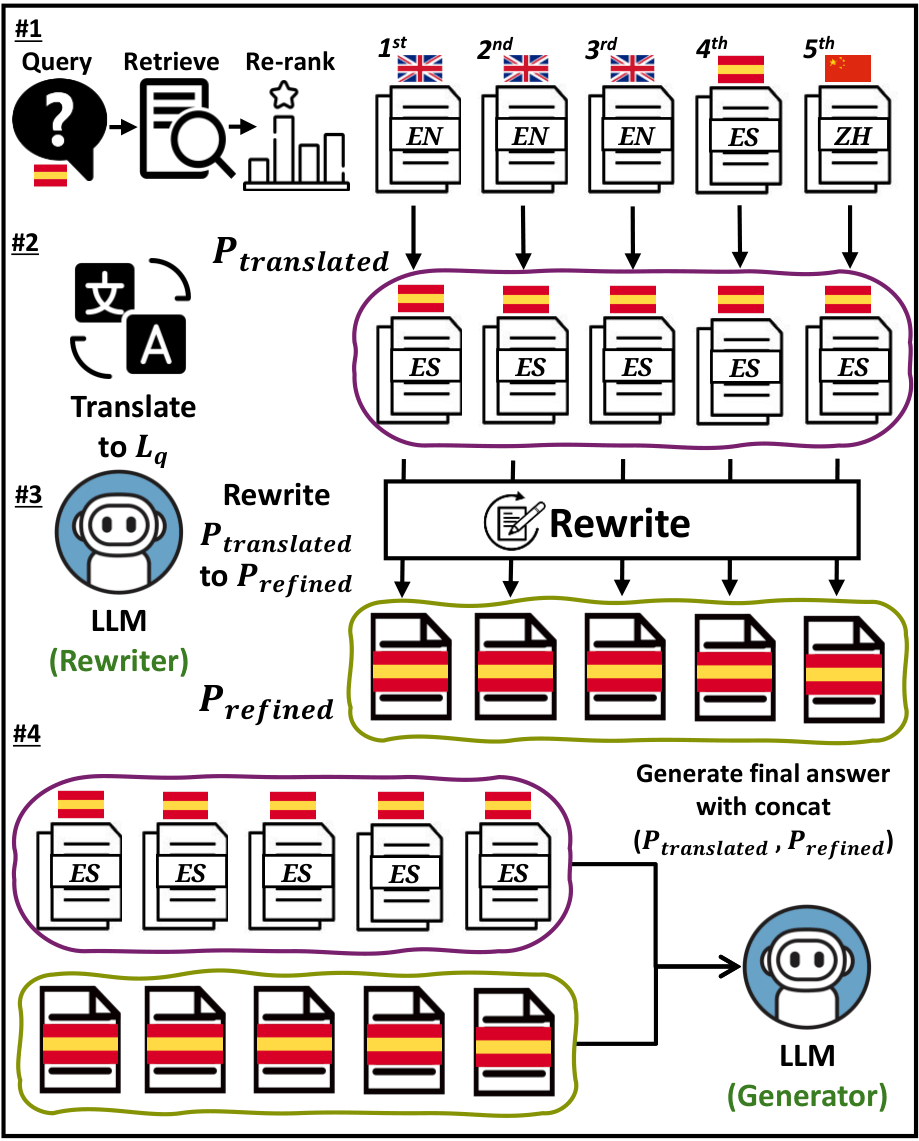
Mitigation
How can we mitigate language preference to improve overall mRAG system performance?